
Yes, UI/UX Is Worth It:
Investigating Scalable Productivity of UX Research Data with Machine Learning
2024 Senior Thesis Research for Princeton University Computer Science Department
Skills
Machine Learning • Research • UX
Team
1 advisor
Outcomes
Published a year-long machine learning research project, using UI screen data and experimental design.
Abstract
UI/UX is one of the most relevant fields of the decade, taking the tech industry and general public by storm. The popularization of UI/UX following historical deprioritization of the user has proven to yield immense returns for users and businesses. However, many companies still show reluctance to invest in UI/UX due to perceived unimportance, cost, and unscalability of UX research methods central to learning about the user’s perspective. This paper proposes a novel approach to increasing the scalability and productivity of the UI/UX field by capitalizing on large repositories of unused UX research data.
This investigation utilizes the Rico UI image dataset and implements a 99-participant survey that labels UI screens with a usability score, in order to emulate the kind of data generated by the most prevalent UX research practice: usability testing. The feasibility of modeling relationships between whole UI screens and user experience data given existing UI representation methods is evaluated using linear regression on layout-based, pixel-based, and structure-based UI vectorizations. This paper’s research process offers an explorative assessment on the sufficiency of current literature for large-scale, cross-context machine learning applications on UI data, and brings to light the future research necessary to support this imminent but unexplored task.
Read the paper here.

From Amazon’s “The Trillion Dollar UX Problem: A Comprehensive Guide to the ROI of UX”
The Immense Value of “UI/UX”
The rise of UI/UX came with the impactful realization that companies don’t always know what users want and need.
Tech companies’ misconceptions and assumptions cost users significant frustration, inconvenience, and time. Investing in UI/UX could make a world of a difference against competitors.
Even small changes rectifying and improving user experience have provided immense returns to businesses, customer satisfaction, and the digital product market.
But, companies are not investing in necessary research.
Why? UX Research is immensely valuable, but the process is not scalable.
Companies often focus on efficiency and scalability.
Businesses opt for broadly-applicable principles or methods for application at large scales, as well as replicable systems with clearly-defined target objectives or destinations.
UX Research aims to take the time to closely examine users on a smaller scale.
Involves taking a step back and reexamining preconceived notions, supplementing with new insights. Rather than a clearly-defined destination, the goal is the practice itself and findings are products of good research.

The Key Idea
Scalable learning from large amounts of historical data is a primary strength of machine learning applications in many other fields, but it has not really been explored for UX research.
By using machine learning to capitalize on large repositories of UI data, UX research data that otherwise goes unused can be more profitable and scalably productive.

Problem Background
“User testing” or “usability testing” is one of the most commonly practiced user research methods.
User tests use numerous product or prototype UI screens to test a participant, gathering quantitative and observational data as participants complete tasks emulating the product’s intended use.
The method is prevalent in late-stage development to at least identify refinements that recover product value, even if a team did not invest in early stage research.
Overall, user tests and researchers are broadly interested in their products’ usability.
The scope of user testing and its data is contained within individual projects cycles and products, having a rather short period of activeness or utility.

A tree map of UX research practices identified by Martinelli et al., where size of rectangles indicate occurrence of the research practice in literature.

One user test is made of many UI screens.
Across sprints, projects, products, and companies, this amounts to a large and growing repository of UI data in the tech and design space.
Current ML applications for UI/UX focus on workflow automation, not garnering value from existing data.

Existing workflow automation approaches.
There’s a lack of approaches investigating methods to capitalize on collected data.
My Approach
The Question
Can we use ML to learn meaningful relationships and draw value from large UI screen datasets?
The Goal

Assess existing UI representation methods on a cross-context downstream task of predicting usability scores.
This approach allows an evaluation of existing methods and technology.
While other fields use ML to benefit from historical data, such an approach for UI/UX is under-explored. This exploration illuminates what working with large-scale UI data might look like and the feasibility of the task given existing literature.
A large-scale approach provides a new angle for the UI/UX discipline.
UX research’s small-scale strengths contrast against a background of rapid automation, but it can be enriched by larger patterns and findings learned with ML whilst preserving the integrity of UI/UX’s core values.
What is the relationship between UI screens and perceived usability?
This study’s experimental approach tackles the unknown of what aspects of UI screens correlate to and inform human experiences of interface usability. Can a machine learn the relationship? What technologies might we need to develop?
Components of Approach

[ 1 ]
This study’s dataset is processed, cleaned, and analyzed for characteristics that may inform experimental design, model performance, or results. Analysis of the data is also key to understanding the task’s complexity.
[ 2 ]
There is a lack of existing data that captures user experience. I designed a controlled experimental survey to label the UI image dataset for supervised learning with a numerical usability score that emulates the objective of user tests.
[ 3 ]
UI images are vectorized using various methods of feature extraction for model training. This component investigates currently available UI representation methods and features’ relevance to usability, as indicated by ML models.
Q.
What does “vectorize” mean?
Put simply, an n-sized vector is like an ordered set of n numbers. When an image (or any type of data) is vectorized, a succinct vector of a chosen size is computed to represent the more complex form. While they may mean nothing to us, these vector representations are better suited for computations.
Implementation
UI Data Collection • Usability Labels & Survey Design • UI Vectorization • Model Training
UI Data Collection
Rico Dataset (2017)
Largest mobile app design dataset, and the only reputable dataset of its scale.

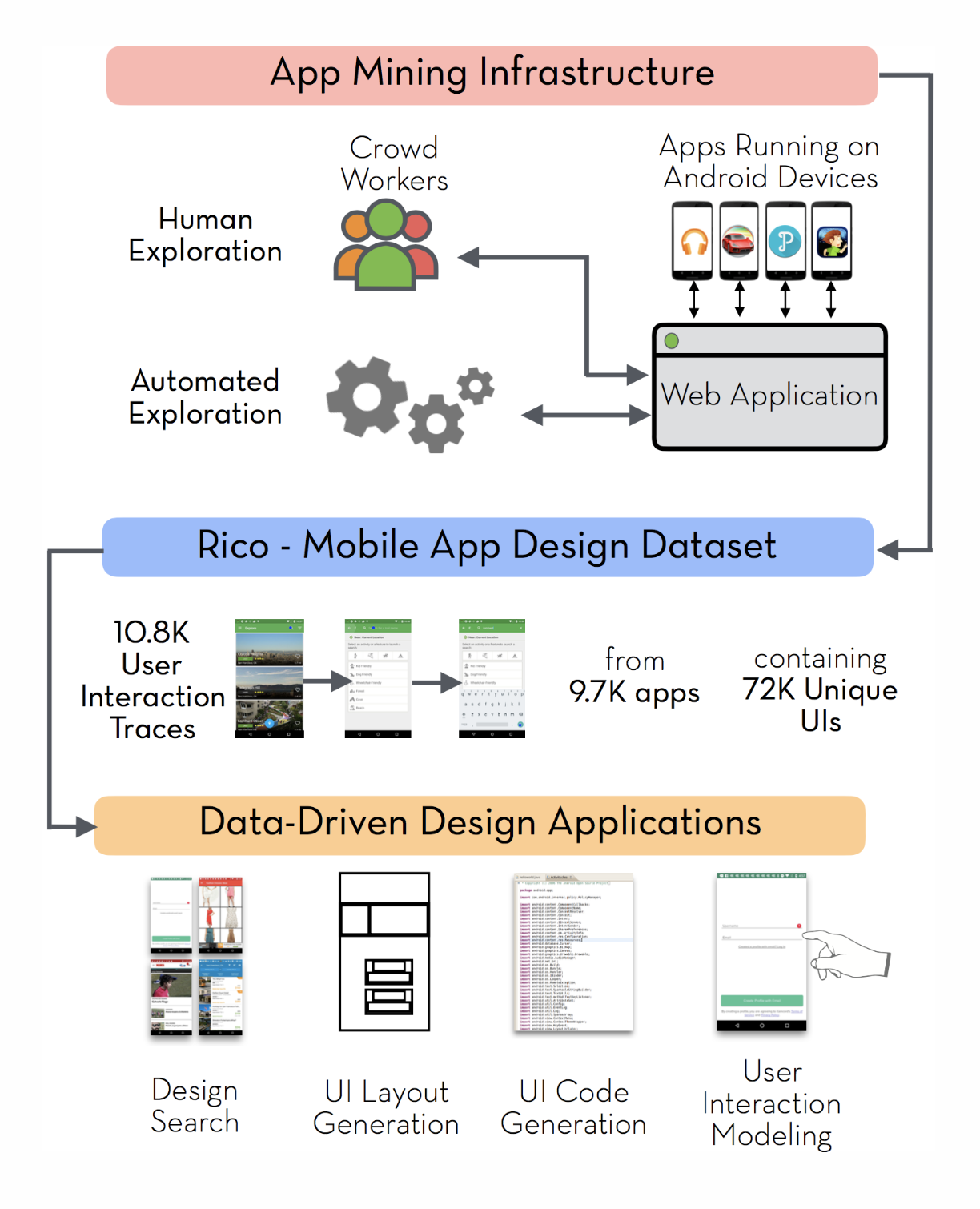
Made to support data-driven machine learning research on UI
72,219 unique UI images from 9,722 Android apps spanning 27 mobile app categories
Uniquely created by crowdsourced workers and automated agents
The Rico UI data was thoroughly cleaned and processed, as this paper’s dataset must primarily be informative for human-facing labeling and suitable for a controlled experiment.

UI screenshots from the Weather, Shopping, and Music & Audio categories.
UI app categories exhibit vast variations in design and semantics, so one category was chosen for a focused and controlled investigation.
While familiar and relevant, Weather UI rely too heavily on data visualizations. Shopping UI are too homogenous in layout, differentiated primarily by aesthetic.
The Music & Audio category provides 2,533 relevant and well-defined but sufficiently variable UI.

The CLAY pipeline.
1. CLAY (2022) Refinement
Li et al.’s CLAY pipeline improves the quality of large-scale UI datasets like Rico through a two-step binary and multi-class classification denoising algorithm.
Invalid Rico UI data eliminated by the CLAY pipeline are cleaned from the Music & Audio dataset.

2. Manual Cleaning
I manually cleaned images based on 6 validity criteria – a process that took 40 hours over two weeks – to confirm that they were adequate for the participant survey.
This paper utilizes a final dataset of 1,663 UI screen images from Music & Audio mobile apps.

Usability Labels & Survey Design
The Survey
For labelling, participants are shown UI screens from the dataset and asked to evaluate their usability on a scale.
The task is intentionally simple in order to reduce overthinking and prevent inconsistency or noise.

“Usability” was clearly defined given the non-interactive still images and participants’ differing exposure to UI/UX.

The scale was clearly defined to collect informative and relevant responses, rather than just 1 to 5.

Data Labeling Process via Survey
1,663 images were randomly split into batches, then evaluated by 99 student survey participants. Each participant evaluated 50 screens, spending an average of 15 minutes. Thus, each screen was evaluated by three participants, informing its usability score by taking the average score response.
Once all UI images were labeled with a usability score, I found that:
Both the participant responses and the resulting score labels for the UI data were very normally distributed.
<5 UI screens received a unanimous average score of 1.0 or 5.0.

Below are some examples of UI screens and their corresponding usability score labels.

UI Vectorization

In this paper, I use 3 types of vectorizations.
Each type uses different aspects of UI screens to compute vectors, allowing me to use and compare representations based on different features.
Rico vectors are precomputed in the Rico Data Repository. For ViT and Pix2Struct vectors, I used pre-trained models.

Visualization of the dataset vectorization.
Model Training
Model
This paper uses linear regression to model the relationship between UI screens and their score labels.
Evaluation Metrics
MSE, RMSE, and MAE, which are all computed differently but all provide a measurement of how far the model’s predictions for the dataset are to the correct score labels. These scores are also known as “loss”, such that higher loss indicates the model’s predictions are further off.
Concerns
Refinements
Vectors computed by ViT and Pix2Struct are so large (768-size)! What if all those features are confusing rather than informative for the model to learn?
Feature selection is a method to eliminating less informative features representing the data. SelectKBest reduces a dataset of 768-size vectors to k-sized vectors of the k best features.
The ViT model used to vectorize our data is was trained on natural images. It may not be specialized for UI data as it just uses pixels.
Fine tuning is a method to make a general-purpose model more suitable for a specific task. The general image model ViT could benefit from fine tuning for this specific task on UI images.
The distribution of our data gives the model so many more score 3 UI to learn from than 1’s or 5’s. What if these data points are neglected?
Oversampling is a method to computationally create more data points or samples of an underrepresented data category. More data points of scores 1 and 5 could help the model learn.
Sample weighting is a method to prioritize certain data categories over others. Weighting score 1 and 5 data higher, makes them more important to the model’s learning.

Visualization of data oversampling.
Model training intends to answer the following questions:
How well does the model perform?
How do the refinements affect performance?
What does that say about how the data is learned?
Results
Model performance across 3 data vectorizations and all intervention methods.
Q.
What do these numbers mean?
The performance of our linear regression models are measured by regression loss metrics (MSE, RMSE, MAE). Very roughly speaking, the values indicate on average how far off the model’s prediction is from the actual data point’s score. The unit is roughly similar to one score interval.
While performance metrics tell us how the models perform overall, it doesn’t give us insight into how the models learned and why they perform the way they do. For this, we need to look at residuals.
Residuals are the exact error between a model’s prediction and the true label.
residual of a data point = its label score – its predicted score
( EX- residual of UI #341 = 4.0 – 3.0 = -1 )
Examining the residuals provides a more detailed look at the model’s predictions and behaviors for each data point.
Most ideally, we want residual to be around 0 no matter the category of score label, with data points are neatly clustered along that residual = 0 line.

Let’s look at the residual graphs for every data vectorization type. We compare residuals for scenarios when the model was trained on data with no intervention, feature selection, and oversampling.

Q. What is the model’s behavior?
The model has wrong behavior of predicting at – or near – the most likely score label of 3.
Q. Why does feature selection yield better performance? Why do Rico vectors yield better performance?
Because the model becomes better at learning the wrong behavior.
Looking at performance metrics alone, the table values showed that fewer features – or smaller vector sizes – improve performance most. Feature selection is most effective and Rico (raw size 64) generally does better than ViT or Pix2Struct (raw size 768).
But the residuals reveal the same 3-prediction behavior. It appears that fewer features improves performance not by allowing better UI-score relationship learning, but rather by making it easier to do the wrong thing.
Q. So, how did these models learn?
They learned that in the data it was given, predicting 3 is the best bet for performing well and avoiding loss. But, they didn’t seem to learn much about the screens themselves.
The UI/UX field and my participant survey demonstrate that there is a real and important relationship between the design of a UI screen and perceived usability. However, the models here are not able to use the provided data to learn a relationship from which to make its predictions.
The Key Finding
Results indicate the inadequacy of UI vector features for modeling. Refinement methods improved performance, but low and high extremes of the scoring scale reveal the model’s fundamental inability to learn meaningful relationships from the features.

Discussion
Using machine learning for productivity and scalability of UX is unfortunately unexplored, and this paper brings to light the resources available to drive large-scale UI experience modeling and where current literature and technologies fall short.
Improvements in UI Representation
Layout-based, pixel-based, or structure-based representations of UI images were inadequate features for modeling our usability metric.
This suggests that the features of UI screens correlate most to usability may be either different from or more complex than the features captured by current UI image representation approaches.
Future work might involve developing new representations or assessing other existing vectorization methods like GCN-CNN or Screen2Vec.
Improvements in UI Datasets
Rico is a valuable dataset and the only one of its kind, but it still lacks in quality.
Despite the CLAY pipeline, 24% of Music & Audio screens were still eliminated manually.
Many screens had large obstructive advertisements, browser pop-ups, or empty-state screens with little to no information.
While CLAY’s Rico screens are structurally the same as real usability testing data, there are significant qualitative differences.
The creators of the Rico dataset warn:
“Unlike static research datasets such as ImageNet, Rico will become outdated over time if new apps are not continually crawled and their entries updated in the database.”
However, it’s difficult to find work in the 5 years since Rico’s release that significantly updates, maintains, or expands Rico.

While the data does not pose technical problems in machine-oriented research, it’s averse enough to affect human-facing evaluation.

Although there remains much work to be done, further exploring the potential for using machine learning to harvest more value out of data generated by UX research can be…
…An avenue for producing the value to secure companies’ investment.
…An opportunity for discovery of new patterns and insights about digital interfaces as an interactive stimuli that can supplement research and design.
For all the good details, head to this page here. ☜